Blog
Wie Maschinen sehen können
Von Daniel Zettler am 3. August 2021
Wie in einem vorhergehenden Blogbeitrag dieser Reihe angesprochen wurde, hat das maschinelle Sehen vor allem in den letzten Jahren große Fortschritte gemacht. Mittels Deep Learning ist es möglich, robuste Systeme für die Objekterkennung in Echtzeit zu erschaffen. Dieser Artikel wird vor allem die technischen Hintergründe behandeln. Wie kann man mittels Deep Learning Objekte auf einem Bild erkennen und richtig lokalisieren?
Blaupause Gehirn
Um Künstliche Neuronale Netze zu verstehen, ergibt es Sinn die biologische Inspiration zu betrachten. Ein erster Ansatz, Neuronen, wie sie in den Gehirnen von Tieren und Menschen zu finden sind, mathematisch zu modellieren, fand bereits in den 1940er Jahren statt. Ein biologisches Neuron kann man sich als Speicher für elektrische Impulse vorstellen. Jedes Neuron ist mit bis zu 30000 anderen Neuronen verbunden und erhält darüber Eingabe-Impulse.Überschreitet die Summe der ankommenden Signale einen bestimmten Schwellenwert im Zellkörper, feuert die Zelle ein Ausgabesignal. Reguliert wird die Stärke der Impulse über die Kontaktstelle zwischen zwei Neuronen (Synapse). Je öfter eine bestimmte Verbindung verwendet wird, umso leitfähiger und damit stärker wird sie. Über diesen Mechanismus, die Signale zu gewichten und die dazugehörigen Gewichte zu verändern, ist das Gehirn in der Lage zu lernen.
Von der Realität zum Gehirn
Tatsächlich funktionieren einfache Künstliche Neuronale Netze (KNN) sehr ähnlich wie oben beschrieben. Die Eingabe sind in diesem Fall keine elektrischen Impulse, sondern numerische Werte wie beispielsweise Daten in Zeitreihen oder die Werte von Pixeln eines digitalen Bildes. In der Abbildung werden beispielsweise fünf Eingabewerte multipliziert mit einem individuellen Gewicht an das (einzelne) Neuron weitergegeben. Im Neuron selbst werden alle ankommenden Produktwerte addiert und die Summe dient als Eingabe für eine Aktivierungsfunktion. Diese Funktion simuliert den Schwellenwert eines biologischen Neurons und berechnet damit den finalen Ausgabewert des Neurons. In der Abbildung würde es beispielsweise Sinn ergeben, +1 auszugeben, wenn die Summe der Signal größer 0 ist, und -1 in allen anderen Fällen. Damit kann dieses einfache Neuronale Netz zwischen zwei verschiedene Zustände (+1 und -1) basierend auf der Eingabe unterscheiden.
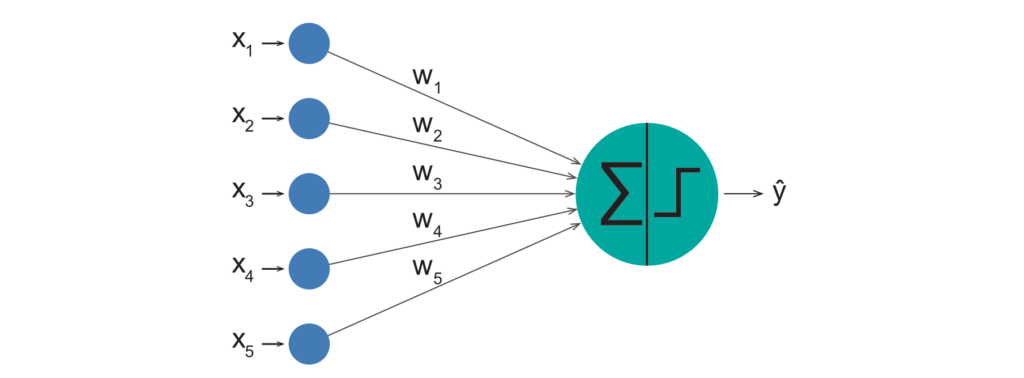
Entscheidend sind damit also die Gewichte, von denen die Ausgabe des gesamten Netzwerks abhängt. Je nach Beschaffenheit der Eingabedaten und der gewünschten Ausgabe, müssen passende Gewichte gefunden werden. Das Ermitteln von möglichst optimalen Gewichten wird Training genannt. Für das Training werden (viele) Beispieldaten mit Paaren aus Eingabewerten und korrekt zugeordneten Ausgaben benötigt.
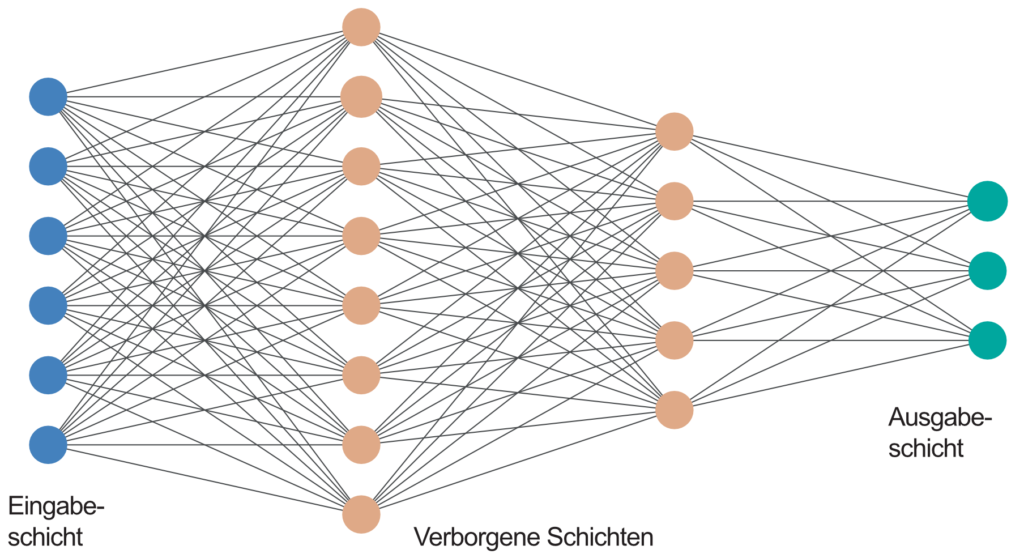
Um komplexere Zusammenhänge abbilden zu können, muss auch das KNN komplexer werden. Anstelle eines einzigen Neurons treten eine ganze Menge von Neuronen aufgeteilt in mehrere Schichten. Genau auf diesen Umstand bezieht sich das “Deep” in “Deep Learning”: Die enorme Steigerung in Rechen- und Speicherkapazität der letzten Jahrzehnte hat dafür gesorgt, dass Neuronale Netze immer mehr Schichten erhalten können und damit “tiefer” werden.
Objekte auf Bildern erkennen
Als Eingabe für ein KNN kann man wie erwähnt die einzelnen Pixel eines digitalen Bildes verwenden. Allerdings benötigen wir für die sinnvolle Verarbeitung von Bildern mächtigere Modelle, die in der Lage sind, effizient Strukturen auf den Bildern zu finden. Für diese Aufgabe werden Convolutional Neural Networks (CNN) eingesetzt, die hauptsächlich im Bereiche Computer Vision Anwendung finden.
Ein CNN ist ein Netzwerk, das als Eingabe ein Bild bekommt und dann Schritt für Schritt Merkmale identifiziert. Man kann ein CNN also mit einem Filter vergleichen, der aus einer großen Menge an Informationen (den “rohen” Pixel der Eingabe), sich nur die Merkmale extrahiert, die für eine korrekte Einordnung notwendig sind. Soll das Netzwerk beispielsweise Katzen und Hunde erkennen können, macht es Sinn, nur die Strukturen im Bild zu betrachten, die einer typischen Katze bzw. einem typischen Hund entsprechen. Wie macht ein CNN das aber nun?
Das geschieht wieder über das Training des Netzes – man könnte sagen, hier lernt das Modell die Unterschiede kennen. Und das Prinzip ist sogar relativ einfach: Man zeigt dem CNN ein Bild mit einer Katze, anschließend gibt das Modell eine Vorhersage aus. Sagt es “Katze” voraus ist alles in Ordnung, ist es allerdings “Hund” müssen die Filter angepasst werden. Damit dieser Mechanismus gut funktioniert benötigt man allerdings viele (tausende) Bilder.
Ein CNN kann seine Filter jeweils dem Problem entsprechend anpassen und geht dabei sogar hierarchisch vor. Während in den ersten Schichten noch recht einfache Muster wie horizontale und vertikale Linien gefunden werden, können diese in späteren Schichten zu immer komplexeren Formen zusammengesetzt werden. So könnte sich ein CNN bei der Unterscheidung von Hunden und Katzen beispielsweise auf die Form der Ohren oder Augen zur Unterscheidung spezialisieren.

Objekte lokalisieren
Grundsätzlich kann ein CNN nur erkennen, ob sich etwas auf einem Bild befindet, nicht aber an welcher Position. Für letzteres gibt es verschiedene Strategien. Ein naiver Ansatz wäre es, dem CNN jeweils nur Ausschnitte des Bildes zu zeigen, auf denen man Objekte vermutet. In einem zweiten Schritt kann man dann jeden Ausschnitt auswerten und feststellen, ob sich darin ein Objekt befindet, das man auch wirklich erkennen möchte. Das Problem dabei ist, dass dieses Verfahren nur sehr langsam ist, wenn man z.B. von mehreren tausend Ausschnitten pro Bild ausgeht.
Ein moderner Ansatz ist es, auch diese Aufgabe von einem weiteren Neuronalen Netz übernehmen zu lassen, das auf der Ausgabe des CNN zur Merkmalsextraktion basiert. Damit muss das gesamte Bild nur noch ein einziges Mal das CNN durchlaufen. Die angehängte Neuronale Netz ermitteln dann effizient sowohl die Position als auch die Klasse von vorhandenen Objekten.
Der nächste Artikel dieser Reihe wird sich, nach der vielen Theorie, um die Praxis kümmern. Unter der Prämisse ein eigenes System zur Objekterkennung zu erstellen, wird näher auf das Training von aktuellen State-of-the-Art Deep Learning Architekturen eingegangen.
Wollen Sie in Zukunft benachrichtigt werden, wenn es wieder einen neuen Blogartikel gibt?
Folgen Sie uns auf LinkedIn und bleiben Sie auf dem Laufenden.
Bringen Sie Ihr Unternehmen auf die nächste Stufe!
Wir entwickeln KI-Lösungen für den innovativen Mittelstand.